Design Distributed Cache - System Design Interview
Problem statement
For a typical web application, client makes a call to a web service and web service makes a call to data storage.
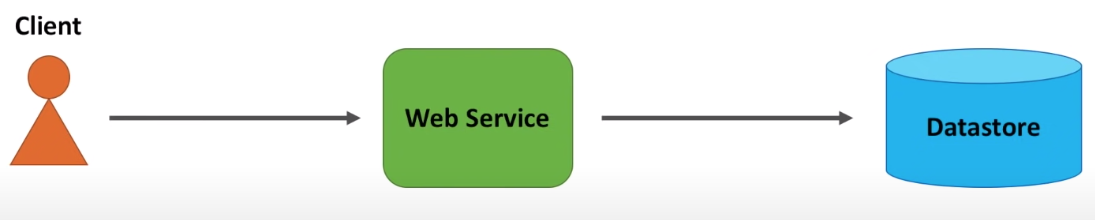
Potential Problems:
- repeated requests keep consume resource
With cache (in memory cache), web service will first check cache before hitting data store.
Benefits:
- the system might still work a short period of time if data store is down
- the latency will be reduced
- repeated requests won’t consume resource
The cache needs to be distributed because the amount of data is too large to fit into the memory of a single machine. We need to split the data and cache it in several machines.

Requirements
Functional
- put (key, value)
- get (key)
For simplicity sake, assume key and value are string.
Non-Functional
- Scalable: scales out when requests and data increased
- Highly available: survive hardware and network failures
- Highly performant: fast put and get
Tip:
- if design system that data persistence is important, also think about durability as non-functional requirements
- start from simple design and evolve it with the communication with the interviewer
Design
Start with simple local cache
In memory local cache for a single server
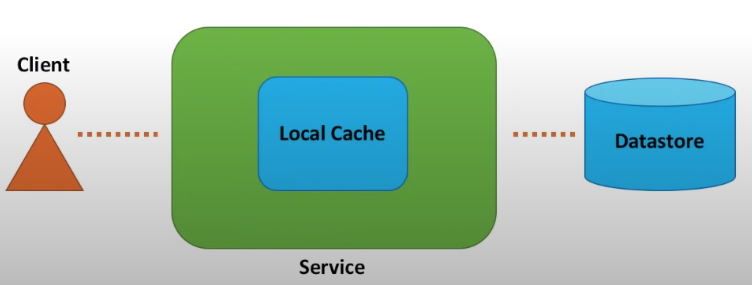
For local cache, hash table will be the suitable data structure. When cache reaches its size limit, we need to find some way to evict old data.Evicion policy includes, e.g. LRU (least recently used).
For LRU cache, we need another data structure to track which data are used recently. It’s like some queue that can add and delete in constant time, which is doubly linked list.

| |
Step into distributed cache
Dedicated cache cluster vs Colocated Cache

How to choose a cache host
- naive approach that using Mod
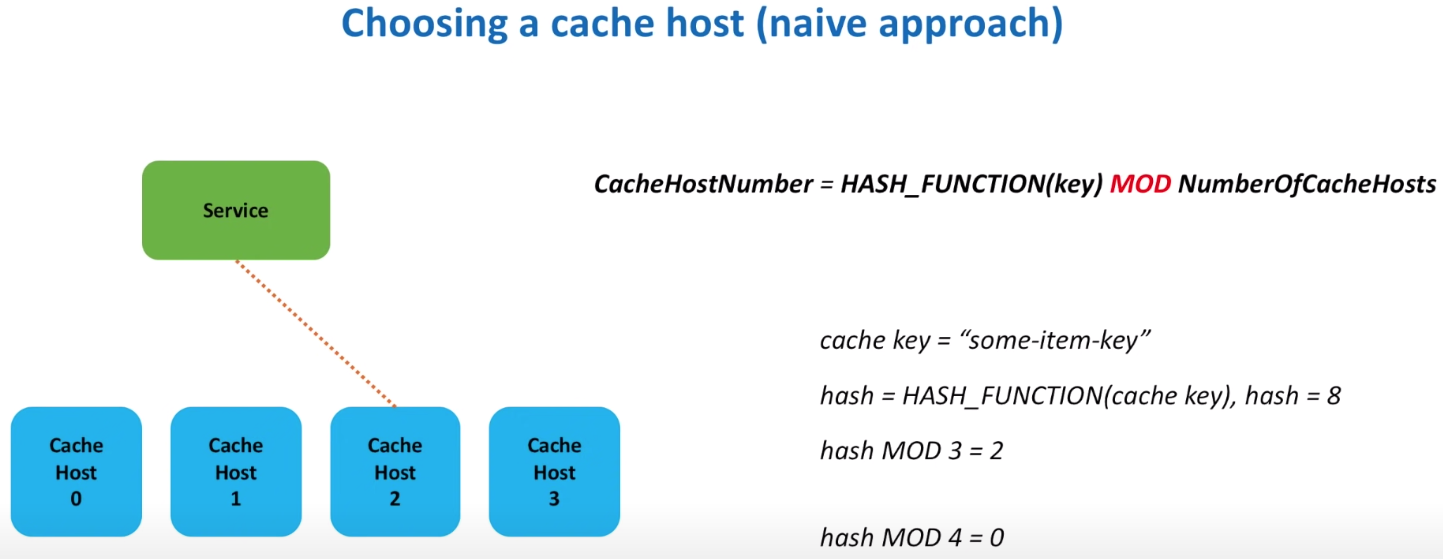
Problem is the mod result will be total different if we add new host to the cluster which results huge cache misses.
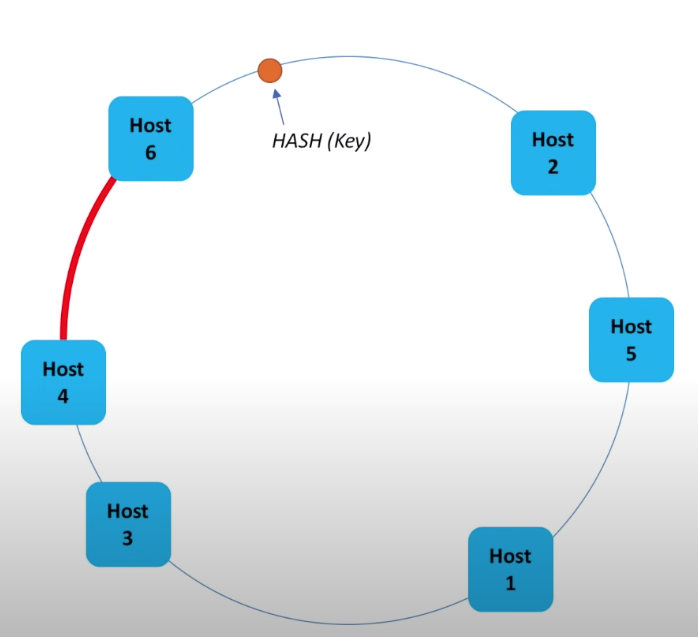
- consistent hashing
Each host is only responsible for the counter clockwise (or clockwise, doesn’t matter) hashing value space till its next host.

To find the host for an item, calculate its hash and looking backward to find the target host.
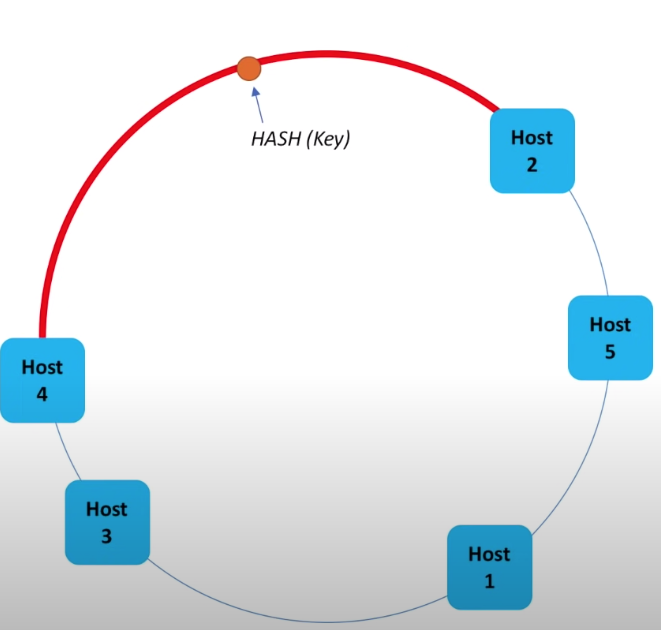
If a new host is to be added, e.g. host 6 below, it’ll be only in charge of a subset of host 4. So the number of items need to be rehashed is limited and otehr hashing value won’t be impacted.
Who is responsible for choosing host
It’s cache client that chooses host. Cache client has the knowledge of list of hosts.
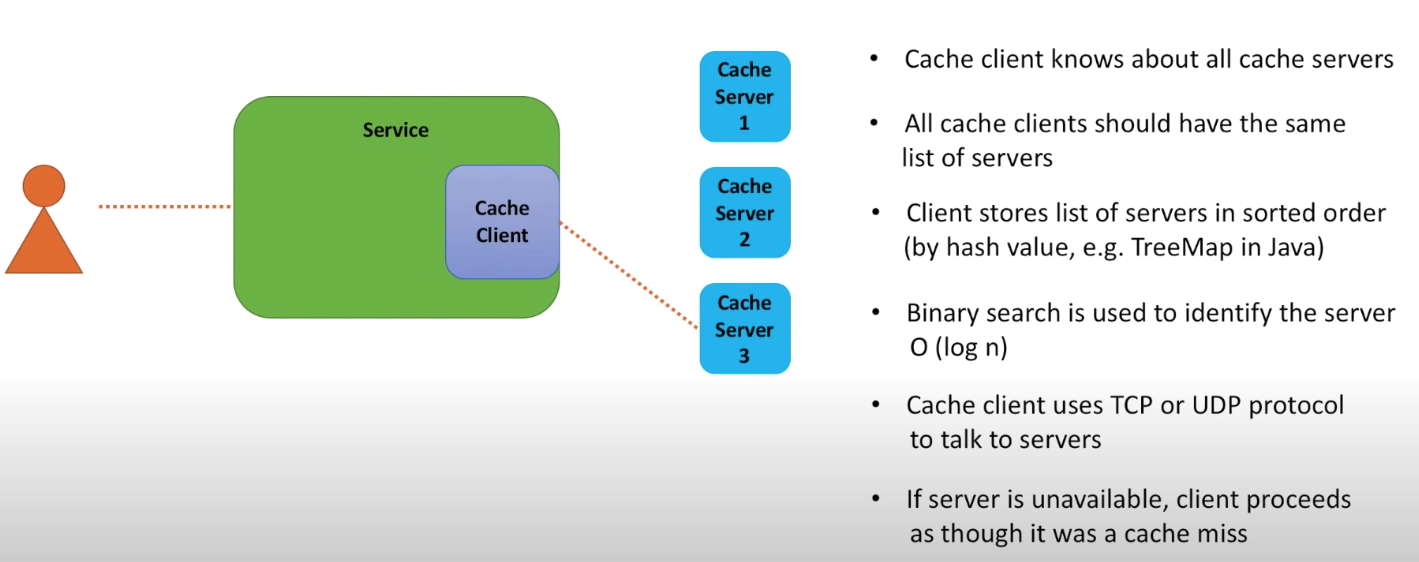
The reason of using binary search is that if you looks for key 100, you need to find the cache server that is in charge of a range including the value 100. Assuming it’s clockwise, the value of host IP hashing will be >= 100, e.g. 123. So you’re looking for a cloest host with IP hashed value greater than 100.
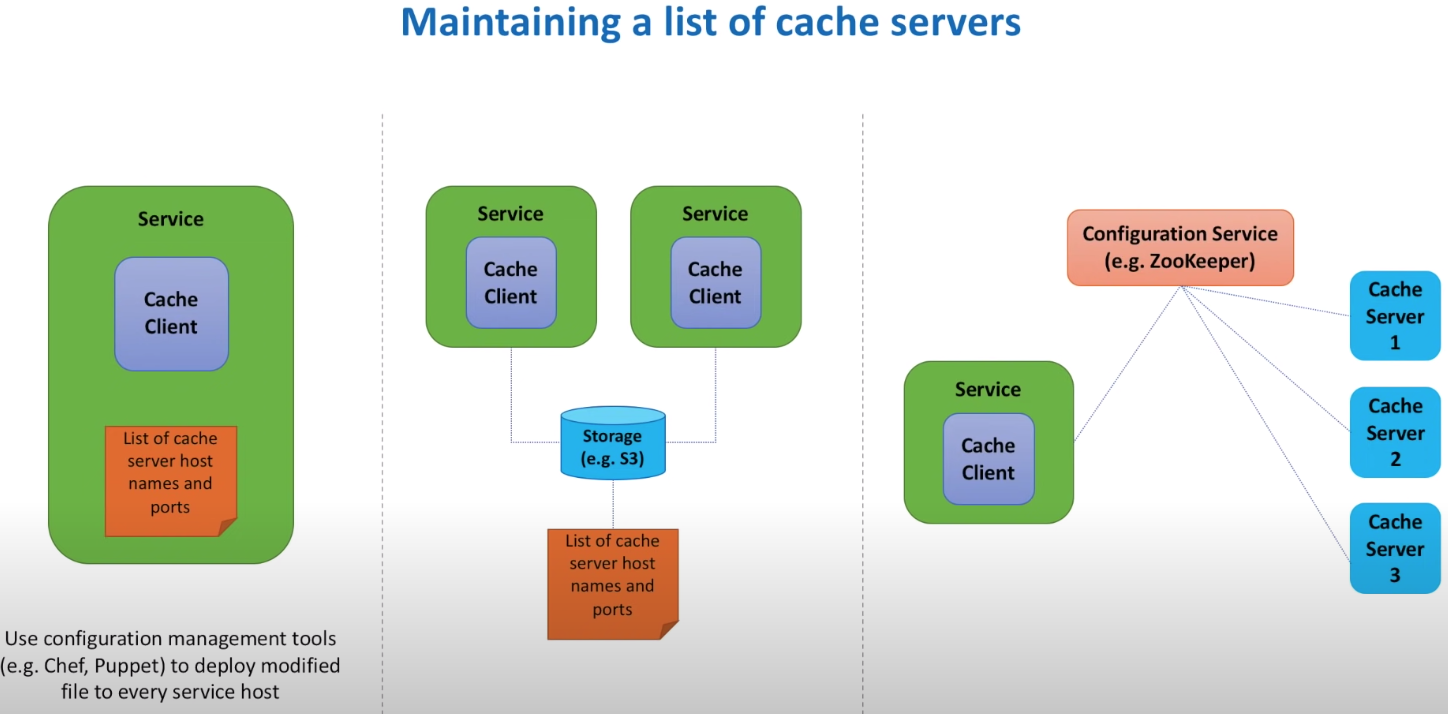
How to maintain a list of cache servers
There are three options
- deploy a configuration file along with service
- save as configuration file in S3 bucket and ask service to read from the S3 bucket
- have a configuration service that maintain the healthy cache servers list by send heart beat requests and ask service to call the configuration service to get list of cache servers
Achieve high availability
Up till now, the performance requirement is satisfied. Scalability is also achieved, as we can create more shards to store more data.
Although the potential problem is that some of the shards might be hot. Adding more shards doesn’t necessarily resolve this problem because a new shard will take some load from a shard, which might not be the hot shard.
Also the high availability is not achieved.
Data replication can resolve this problem.
We can have master and read replicas. And in the configuration service, we can implement leader election mechanism that it monitors both master and read replicas and promote read replica as leader if the previous leader is down.
Zookeeper is a good tool for configuration service.
The data replication is asynchnonious, which means response is returned before data replication is finished. It’s possible that data is lost when the leader is dead before it syncs data to replicas. In this case, it can be treated as cache miss. It’s acceptable to have such case and our service should be design to tolerate such case.

What else is important
- Consistency
Because data replication is async, it’s possible that client has cache hit when it reaches leader but cache miss when it reaches replicas.
The consistency issue can be fixed by forcing synchnonious replication but the trade off is increased latency and system complexity.
- Data expiration
If data wouldn’t reach cache size for a while, it’s possbile that data in cache become stale. This can be addressed by adding some metadata, like TTL (time to live), and use it to identify stale data.
There are two ways to do so, Passive way that when client access the stale data, evict it. Active way is that having some jobs scheduled to run in some intervals to evict stale cache. Because the number of cache items are huge, we need to use probablistic algorithm to do so.
- local and remote cache
To further improve the performance, we can have cache clients to have local cache and only check remote cache when local cache misses. So in this way, all implementation details are hide behind the cache client.
- security
Cache should not be exposed in internet
monitoring and logging
- like, faults, number of cache hit and miss, CPU and memory usage, network IO
Consistent hashing drawback
Consistent hashing might have Domino effect, which happens when one cache server is down and it’s load shifted to its next neighbour and the extra load makes the neighbour down as well and so on.
Another drawback is that cache servers might be in charge of different load as it’s not evenly distributed in the circle. It can addressed by adding each host to multiple place of the circle.
The circle is a logic structure that helps us assign owners for a range of hash keys.
Recap
